Event Sourcing under steroids!
I have started to play with Amazon Web Services (aka AWS) since some months. I found that AWS has made cloud easy. Really. It is easy to create your web server, to add a database, to manage network security, monitoring, supervision, … They have also introduced a really interesting product: Lambda and the associated pattern: Serverless architecture.
Lambda is the representation of a pure function at server level. You have some inputs, you get some outputs, no state. So, it simplified the scaling of your application. Deployment is fostered with the serverless framework. With this tool, creating an event sourcing application has never been so easy!
Lambda
What is it?
Lambda is a managed service offered by Amazon Web Services. A lambda is just a small piece of code which complies to an interface. It can be written in Python, node.js and java 8. You write a piece of code, you upload it in the AWS cloud and you let Amazon managed aspects like scaling, monitoring, configuration, … and so on. You trigger it with others services like API Gateway or SNS.
For Java, you have [differents way to create a lambda][java-lambda]. One way is to implement an interface:
package org.test;
public class MyLambda implements RequestStreamHandler {
@Override
public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException {
// Your code goes here
}
}From there, you can access to others resources like RDS, DynamoDB, …
Using your lambda
There are differents ways to execute a lambda. Next are events that you can use to trigger or execute your lambda :
- Directly from the AWS console
- When a new DynamoDB record is created, …
- When a new message is created in your SNS topic
- With API gateway
- With SQS. In this case, you will need to use CloudWatch which will pool your queue and call your lambda when a new message is available
- When something is inserted in your S3 bucket
- Kinesis also
Lambdas seem to be the new key component of AWS.
Deployment
You can found a complete example there. First, you need to define a role:
$ echo '{
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow"
}
],
"Version": "2012-10-17"
}' > role.json
$ aws iam create-role \
--role-name handler-execution-role \
--assume-role-policy-document file://role.json
$ aws iam attach-role-policy \
--role-name handler-execution-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
$ aws iam attach-role-policy \
--role-name handler-execution-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaRoleThen, you need to create a deployment package. For java, you can find instructions here.
Eventually, you can deploy your application with the AWS console or with the AWS cli:
$ aws lambda create-function \
--function-name my-lambda \
--zip-file fileb://build/distributions/mypackage.zip \
--role arn:aws:iam::XXXXX:role/handler-execution-role \
--handler org.test.MyLambda \
--runtime java8 \
--timeout 15 \
--memory-size 512
$ aws lambda update-function-code \
--function-name my-lambda \
--zip-file fileb://build/distributions/mypackage.zip You can also rely on the new simplified serverless application model.
Quite simple, yes? But we can do better!
Serverless framework
The serverless framework is designed to simplify lambdas deployment in order to create a complete application. You can install it with npm:
$ npm install serverless -gThen, you can start to create your new application:
$ serverless create --template aws-java-maven --path myAppThis command will create a new java-based lambda application. You can also do it in python, scala, … more info here, even with the go language.
At the root, you can find the serverless.yml file. It contains the description of your application, with the following groups:
- service : your application name
- provider : runtime (java, python or nodejs), region, stage (dev, test, production, …)
- functions : this is where you declare your lambdas
- resources : associated resources like buckets, … used by your lambdas
Event sourcing with lambda and serverless framework
So let’s start with event sourcing and see how lambda and serverless framework make it easy to create my application
Event sourcing?
First of all, what is event sourcing? Event sourcing is an architecture popularized by Greg Young.
As in every classical n-tier architecture, you have a huge database which keeps track of the current state of objects. Most of time, only one big model has been designed representing the domain. More over, most of time, history of modifications are not kept. For example, you can have your debt and credit of your bank account.
With event sourcing, you store events which modify the price. You determine the current state of the object by replaying events associated to this object. Using the same example with the bank account, we can have all the events on your accounts like withdrawing of deposing money. Not only you can evaluate the state of your account by replaying transactions, but you have the whole history in terms of business event (withdraw & deposit). You can use it for future needs (for example, what are the average desposit & withdraw every month?), you can track strange events, you can prove why you are in this current state and so on. You can only go forward, no one is allowed to update the stream of events once it has been written. Really strong and great invariant!
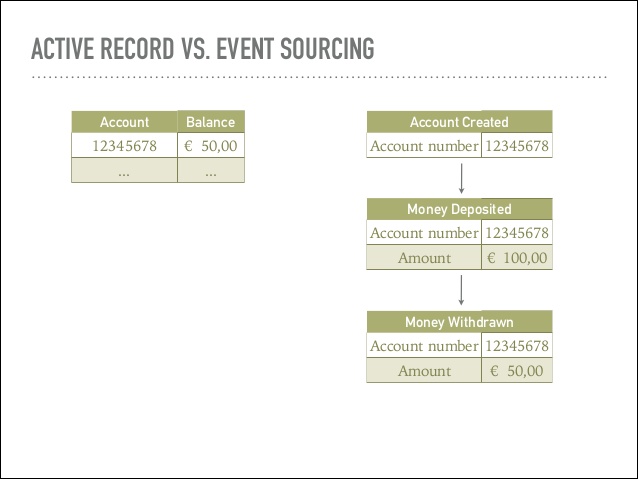
Event sourcing is composed of three parts:
- Write part: it receives commands and issues events. In a functionnal way, we can see a command as : fcommand(state) -> event
- Processing part (also called projection) : take an event and update the state : gevent(state) -> state
- Read part : read the state. h(x) -> state
Event sourcing takes its root into DDD. To built it, you will need to find domains with their bounded contexts and work on each domain to extract business events.
Event sourcing can be though as a way to reveal the intention of your business by clearly using business events into every exchange in the application.
Here is a great presentation of this subject.
Price-tracking application
We are going to use an application for tracking products. For the moment, we are only keeping the state of the price. Prices can increase or decrease. We can imagine a lot of modifications.
The next picture is a simplfied event sourcing architecture with the AWS components :
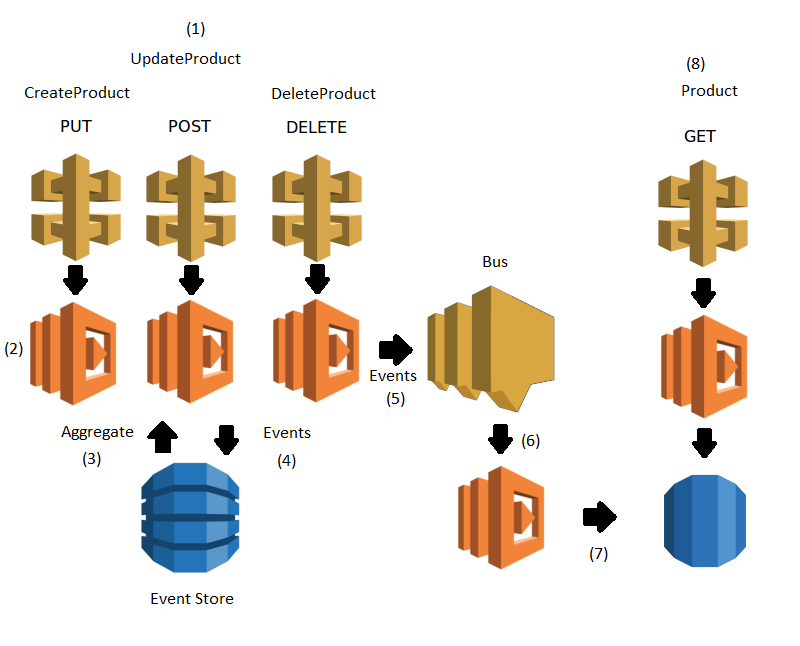
Messages are : # A command is sent (from UI, for example) to modify the product.
- CreateProduct creates a new product with a price
- UpdateProduct indicates the variation in the price
- DeleteProduct makes the product unavailable # Lambdas associated to the command processes it. # First, the aggregate representing the product is retrieve by retrieving all associated events and replaying them # Then, based on the conditions (for example, only a product which has been created before can be update), a new event is created and stored. # The event is also published on the bus to notify everyone that something has happened # The event is read # Data is updated and stored in a way that facilitates the read part. Note that we can have more than one lambda and read format. # The UI can query the informations
Description
I try to keep the processing in one function in order to facilitate the understanding
Reading the query
Your Lambda needs to comply to an interface specified by AWS.
In order to read the query from API Gateway, you need to implement the input/ouput stream interface :
@Override
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
...
}Then, from the input stream, you will receive a json string with a body parameter. You will need to parse this body to get the input parameters
The read side
The read part is really simple. It retrieves the id of product and returns the associated entry in the table. We use a raw JDBC connection to keep a thin and simple database layer.
Example for the query part :
Connection conn = database.getConnection();
st = conn.prepareStatement(QUERY);
st.setString(0, getRequest.getProductId());
st.execute();
ResultSet rs = st.getResultSet();
if (rs.next()) {
return new Response("" + rs.getDouble("price"));
}The processing part
The processing part receives the event and apply some modifications to the data:
@Override
public Response handleRequest(ProcessRequest processRequest, Context context) {
EventType eventType = EventType.valueOf(processRequest.getEvent());
switch (eventType) {
case CREATE:
create(processRequest.getProductId(), processRequest.getValue());
break;
case UPDATE:
update(processRequest.getProductId(), processRequest.getValue());
break;
case DELETE:
delete(processRequest.getProductId());
break;
}
return new Response("OK");
}Depending on the event, we add, update or remove the entry in the read database.
The approach is really naive (with switch).
The lambda implements the RequestHandler interface.
The write side
Last but not the least, the write part. Let’s have a look to the CreateCommand Lambda :
Optional<Product> product = productRepository.getById(input.getProductId());
return product
.map(x -> new Response("Failed to create product, product exists"))
.orElse(createProduct(input));We retrieve the existing aggregate from the repository. If it doesn’t exist, we publish a new product with the event ProductCreate.
Retrieving and building the aggregate:
context.getLogger().log("Input " + input);
Optional<Product> product = productRepository.getById(input.getProductId());
return product
.map(x -> new Response("Failed to create product, product exists"))
.orElse(createProduct(input));As you notice, we rebuilt the aggregate from events. Here, I have not introduced snapshots which allow us to have pre-build aggregates, so getting the aggregate is faster.
The easy part : deployment and test
As you can see, we just have to fill the gap in functions. Deployment is as easy as serverless deploy, rollback is serverless rollback. With informations defined in the file serverless.yml, serverless builds your stack, deploys your code and wires everything.
Some points should be highlighted too:
- Even if it is simple, it is not perfect. DynamoDB is a great database. It can also easily send back all stored events to your lambda. However, primary key system is limited. I can only create a key made of productId and date. If I receive two events at the same time, game over, the entry is updated.
Event Sourcing has a lot of advantages and disavantages. It is not a silver bullet. It is true that you can do so many things :
- Create multiple reads api, so you can tweak each of them separately
- Create new reads parts from the beginning of your history.
- Have everything you need even if you don’t know what you can one day need it!
However, the main drawback is that events you should be well captured and tailored with the business. A common tool you can use is event storming sessions to facilitate this process.